In the history of generative art, there is a “before” and an “after” the year 2021. Before, we had Generative Adversarial Networks (GANs)—unstable, difficult to train, but capable of producing sharp faces. After, we entered the era of Diffusion Models. Suddenly, anyone with a text prompt could generate hyper-realistic landscapes, complex cinematic scenes, and surrealistic masterpieces.
But how does a machine “sculpt” an image out of thin air? The answer lies in a concept borrowed from thermodynamics: the process of reversing entropy.
1. The Core Concept: Sculpting from Digital Static
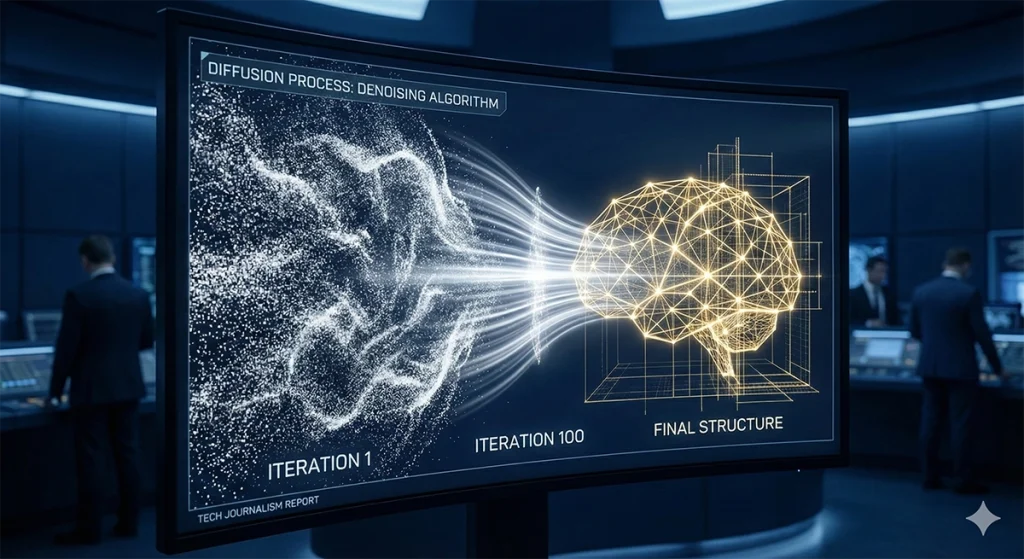
Imagine taking a clear photograph and slowly sprinkling sand over it until the original image is completely buried. This is the Forward Diffusion Process. Diffusion models work by learning how to do the exact opposite: they learn how to brush away the sand to reveal the image underneath.
The Two-Step Dance
- Forward Process (Adding Noise): The model takes a training image and systematically adds Gaussian noise in several steps until the image becomes pure random static.
- Reverse Process (Denoising): This is where the magic happens. The neural network (typically a U-Net) is trained to predict exactly how much noise was added at each step. By subtracting this predicted noise, the model “denoises” the static, slowly revealing a coherent structure.
Instead of trying to create an image in one giant leap, Diffusion models take hundreds of tiny, mathematically precise steps, refining the chaos into order.
2. Latent Diffusion: The Breakthrough of Efficiency
Early diffusion models were computationally expensive because they operated on every single pixel. The revolution of Stable Diffusion came from a technique called Latent Diffusion.
Instead of working in the massive “Pixel Space,” the model works in a compressed Latent Space.
- The Encoder: Shrinks the image into a smaller, abstract mathematical representation.
- The Diffusion Engine: Performs the denoising process within this compressed space.
- The Decoder: Blows the final latent representation back up into a full-resolution image.
By working in Latent Space, the model ignores the redundant details and focuses on the high-level semantic meaning, allowing high-quality image generation to run on consumer-grade GPUs.
3. The Role of the Prompt: Guidance and Conditioning
How does the model know to generate a “cat in a spacesuit” instead of a “mountain at sunset”? This is where Conditioning comes in, usually powered by CLIP (Contrastive Language-Image Pre-training).
As the model denoises the image, it constantly checks its progress against a text embedding (a mathematical representation of your prompt). The text acts as a “magnetic pole,” pulling the denoising process in a specific direction. Every step of the way, the model asks: “Does this version of the noise look more like a cat in a spacesuit than the last one?”
4. Why Diffusion Won: Stability and Diversity
For years, GANs were the gold standard, but they suffered from Mode Collapse—a phenomenon where the model would find one “perfect” image (like a specific face) and generate it over and over again, failing to produce variety.
Diffusion Models solved this through:
- Training Stability: They don’t rely on the “adversarial” fight between two networks, making them much easier to train at scale.
- Sample Diversity: Because they start from random noise every time, the variety of outputs is virtually infinite.
- High-Fidelity Detail: The iterative nature of denoising allows for incredible texture and lighting that GANs struggled to match.
5. Beyond Still Images: Video and 3D
The success of Diffusion hasn’t stopped at 2D images. We are now seeing the rise of Video Diffusion Models (like OpenAI’s Sora) and 3D Diffusion. By adding a temporal dimension (time) to the denoising process, AI can now generate consistent motion, understanding how objects should move through space while maintaining their identity.
Conclusion: Reversing the Arrow of Time
Diffusion models represent a profound mathematical victory. They show us that order can be found in chaos, and that the “arrow of time” (entropy) can be reversed through the power of deep learning.
As we look toward the future of imagin.net, Diffusion models are the bridge to a world where human imagination is no longer limited by artistic skill, but only by the clarity of our thoughts. We have moved from the era of classification to the era of manifestation.
References
- High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
- Source: CVPR 2022
- URL: https://arxiv.org/abs/2112.10752
- Denoising Diffusion Probabilistic Models (DDPM)
- Source: NeurIPS 2020
- URL: https://arxiv.org/abs/2006.11239