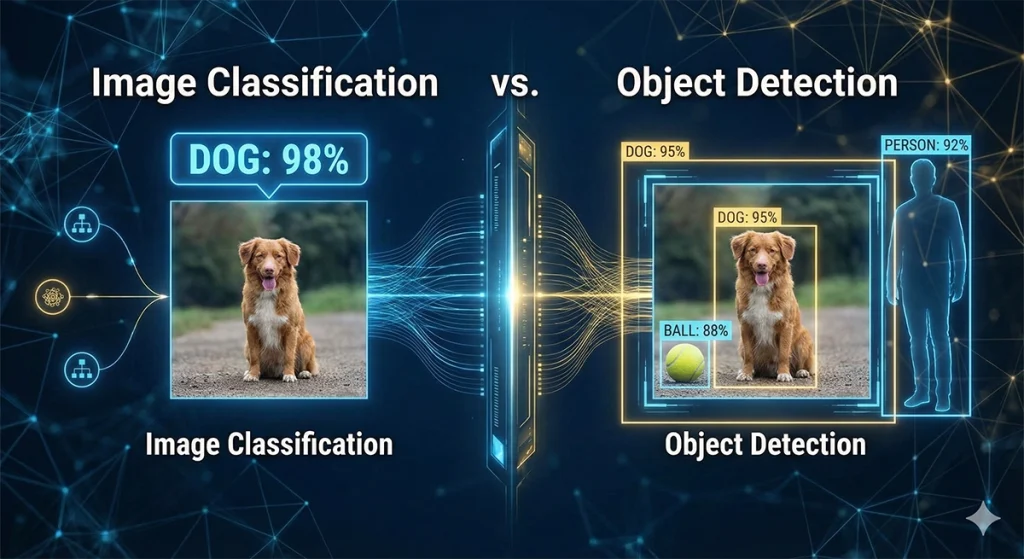
In the rapidly evolving landscape of computer vision, two tasks serve as the foundational pillars for almost every visual AI application: Image Classification and Object Detection. While they might seem similar to the uninitiated, they represent fundamentally different levels of “spatial intelligence.”
For a machine to truly understand a visual scene, it must move beyond simply recognizing what is in an image to identifying where those objects are and how many exist. This guide explores the technical nuances, architectural differences, and strategic trade-offs between these two critical domains.
Image Classification: Assigning a Digital Identity
At its simplest, Image Classification is the task of assigning a single label to an entire image. When an AI looks at a photograph and concludes with 98% certainty that it depicts a “Golden Retriever,” it is performing classification.
The Mechanics of Classification
Classification models—typically built on CNN backbones like ResNet or EfficientNet—take an input image and compress its visual information into a feature vector. This vector is then passed through a “softmax” layer that outputs a probability distribution across predefined categories.
- Output: A discrete label (e.g., “Car”) and a confidence score.
- The Assumption: The model assumes there is a primary subject in the image that defines its identity.
- Key Benchmark: The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) primarily focused on this task, pushing error rates below human performance levels.
While powerful, classification is spatially “blind.” It knows a dog is present, but it cannot tell you if the dog is on the left or the right, or if there are actually three dogs in the frame.
Object Detection: The Geometry of Intelligence
Object Detection is a significantly more complex challenge. It combines Image Classification with Localization. The goal is to identify all instances of specific objects within an image and draw a Bounding Box around each one.
The Dual-Task Problem
An object detector must solve two problems simultaneously:
- Regression: Predicting the coordinates $(x, y, w, h)$ of the bounding boxes.
- Classification: Identifying the object inside each predicted box.
Because an image can contain an unknown number of objects at varying scales and aspect ratios, object detection requires much more sophisticated spatial reasoning than simple classification.
The Architectural Spectrum: One-Stage vs. Two-Stage Detectors
In the world of object detection, researchers generally choose between two primary architectural philosophies, each balancing speed and accuracy differently.
1. Two-Stage Detectors (Accuracy First)
Models like Faster R-CNN operate in two distinct phases. First, a Region Proposal Network (RPN) identifies “interesting” areas of an image that might contain objects. Second, these regions are cropped and sent to a classification network for refinement.
- Pro: High accuracy, especially for small or overlapping objects.
- Con: Slower inference speeds, making them less ideal for real-time mobile applications.
2. One-Stage Detectors (Speed First)
Architectures like YOLO (You Only Look Once) and SSD (Single Shot Detector) skip the proposal phase. They treat detection as a single regression problem, predicting bounding boxes and class probabilities directly from the full image in one pass.
- Pro: Incredible speed, capable of processing video at 60+ FPS.
- Con: Historically struggled with very small objects, though modern versions (YOLOv8, YOLOv10) have largely closed the gap.
Critical Metrics: Measuring Success
Evaluating these models requires different mathematical approaches.
- For Classification: We use Top-1 and Top-5 Accuracy. Did the model’s highest-probability guess match the ground truth?
- For Detection: We use mAP (Mean Average Precision) and IoU (Intersection over Union).
- IoU measures how much the predicted bounding box overlaps with the actual object.
- mAP calculates the precision and recall across all classes, providing a comprehensive score of the detector’s reliability.
Strategic Selection: Which One Do You Need?
Choosing between classification and detection depends entirely on the “downstream” requirements of your AI system.
- Choose Image Classification if: You are organizing a photo library, filtering NSFW content, or performing medical screening where the presence of a single condition (e.g., “Pneumonia”) is the only concern.
- Choose Object Detection if: You are building an autonomous vehicle (need to know where pedestrians are), a retail analytics system (need to count items on a shelf), or a security system (need to track movement).
Conclusion: Toward Semantic Understanding
As we move into the era of Segmentation and Multimodal AI, the line between classification and detection is blurring. Models like the Segment Anything Model (SAM) are taking localization to the pixel level, while generative models like GPT-4o can describe scenes with a spatial awareness that goes far beyond bounding boxes.
Understanding the distinction between classification and detection is the first step in mastering the “Foundations of Computer Vision.” It is the difference between an AI that recognizes a concept and an AI that can interact with the physical world.
References
- You Only Look Once: Unified, Real-Time Object Detection (YOLO)
- Source: CVPR 2016
- URL: https://arxiv.org/abs/1506.02640
- Rich Feature Hierarchies for Accurate Object Detection (R-CNN)
- Source: CVPR 2014
- URL: https://arxiv.org/abs/1311.2524